CNNs
Chapter 02 - Generative Deep Learning Book

Hoje nós vamos avançar mais um pouco em direção ao universo de arquiteturas de Deep Learning relacionadas a IA Generativa. Até aqui, nós já falamos sobre:
- IA Generativa, abordando de forma geral
- Pytorch, explicando um pouco sobre o framework
- Deep Learning, trazendo conceitos básicos úteis para nosso entendimento ao decorrer dos artigos.
E agora, vamos falar sobre Redes Neurais Convolucionais (CNNs).
Por que CNNs?
As Convolutional Neural Networs são o lugar comum por onde nós normalmente começamos a estudar a fim de entender sobre arquiteturas de Deep Learning. Acredito que muito pelo trade-of que elas oferecem, em relação a complexidade vs aplicações.
Entender conceitualmente sobre essas redes neurais acaba sendo mais intuitivo do que entender outras arquiteturas de Deep Learning, como RNNs. Além disso, você consegue utilizá-las para realizar tarefas relacionadas a Visão Computacional.
E um último motivo é que a premissa inicial dessa série de blog posts é tentar caminhar junto com o livro (Generative Deep Learning), e por isso que entramos na arquitetura abordada no capítulo 2.
Conhecimento a priori
No artigo passado… Falamos sobre imagens serem na realidade um tipo de dado que possui uma estrutura atrelada, contrariando o que aprendemos, onde imagens são um tipo de dado desestruturado.
Estrutura aqui, vem muito no sentido da composição dessas imagens, sempre com um “arranjo” de matrizes, onde cada posição desse dado vai representar um pixel.
Uma imagem, além das dimensões de largura e altura (linhas e colunas), também possuem chanels (dimensões). O Pytorch, framework de Deep Learning que estamos utlizando, acaba assumindo uma convenção para quando uma imagem é representada como um tensor:
- N: número do batch de imagens
- C: número de channels
- W: largura
- H: altura
(N, C, W, H). Mais a frente veremos na prática como as imagens são representadas no Pytorch.A estrutura de uma image nos indica que o valor que um pixel pode assumir não é independente do valor do pixel vizinho, em outras palavras, nós iremos ter uma correlação entre os pixels de um determinado conjunto de imagens e eles não podem ser analisados isoladamente. Esse tipo de conhecimento a priori é também chamado de estrutura espacial a priori e é ela que as CNNs tentam “aprender”.
Apenas para ilustrar, se nós embaralhasse-mos os pixels de uma imagem de um número 5, o mesmo ficaria irreconhecível, corroborando para esse conceito de correlação dos pixels. Veja na imagem abaixo:

O que são convoluções?
Convolução nada mais é que uma função matemática que recebe dois inputs: uma imagem e um filtro (também chamado de kernel).
Como saída dessa função temos uma nova imagem.
Mas como é que essa operação pode ser utilizada para treinamento de uma rede neural, e eventual aprendizado de padrões sobre as imagens?
O principal responsável para isso são os filtros. Esse input da função é muito especial e têm a capacidade de reconhecer certos padrões na entrada e realçá-los na saída. Tradicionalmente, os filtros têm sido utilizados em muitas aplicações para capturar padrões ou aplicar comportamentos específicos às imagens, como por exemplo:
- aplicar desfoque gaussiano
- detectar linhas horizontais
- aumentar a nitidez
- capturar as bordas das imagens
Porém, quando aplicados ao deep learning, nosso real interesse é encontrar os melhores filtros que possam criar os melhores padrões para representar os dados de maneira mais adequada. No final, com essa ótima representação, seremos capazes de classificar, detectar ou realizar qualquer outra tarefa relacionada à visão computacional.
As convoluções existem em diferentes dimensões (1D, 2D, …), mas o racional por de trás continurá sendo o mesmo. Veja na imagem abaixo como o filtro vai percorrer a imagem e ao realizar os cálculos vai retornar uma nova imagem.
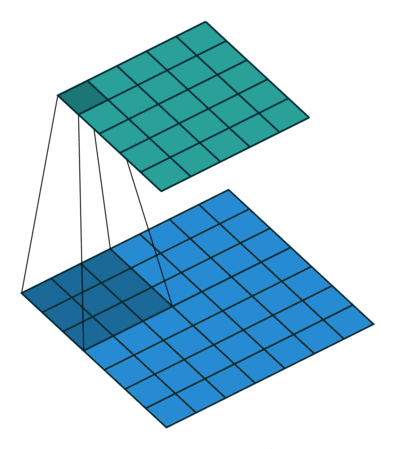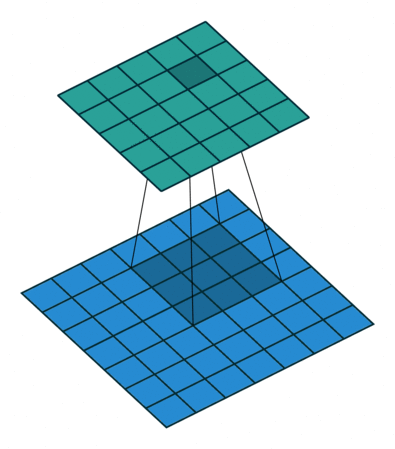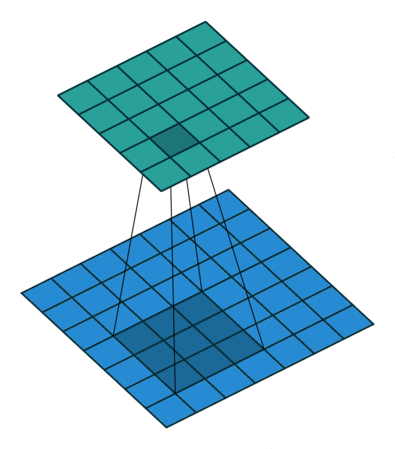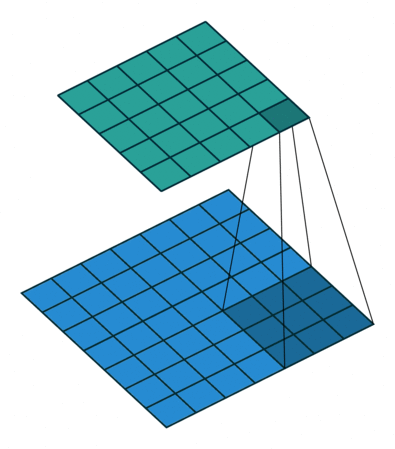
Um ponto importante a observar é que a imagem resultante (imagem em verde), pela pura operação do convolução é uma imagem menor que a original. Como resolvemos isso?
Padding
É justamente para isso que existem os paddings. De forma simples, os paddings vão adicionar linhas e colunas ao redor da imagem original, para que durante a operação de convolução, a imagem resultante permaneça com a mesma dimensão.
O mais comum é o zero-padding, mas as referências citam que podemos utilizar outros tipos também (eu particularmente nunca usei).

Processamento de imagens com convoluções
Como dito acima, convolução é apenas uma operação matemática. Sendo assim, ao longo do tempo a pesquisa científica chegou há alguns kernels que aplicam algumas transformaçẽos em imagens.
Então, vamos realizar um experimento e passar alguns kernels por algumas imagens do dataset mais batido da bolha de data science, MNIST. Para isso, vamos utilizar o Torchvision, ele nos fornece um meio de baixar esses dados e automaticamente criar um objeto Dataset:
Coletando os dados
def get_mnist_dataset(
train_transformers=transforms.ToTensor(), test_transformers=transforms.ToTensor()
) -> tuple[Dataset, Dataset]:
mnist_train_dataset = datasets.MNIST(
root="./data", train=True, download=True, transform=train_transformers
)
mnist_test_dataset = datasets.MNIST(
root="./data", train=False, download=True, transform=test_transformers
)
return mnist_train_dataset, mnist_test_dataset
def get_mnist_dataloaders(
batch_size: int, train_dataset: Dataset, test_dataset: Dataset
) -> tuple[DataLoader, DataLoader]:
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
return train_dataloader, test_dataloader
mnist_train_dataset, mnist_test_dataset = get_mnist_dataset()
mnist_train_dataloder, mnist_test_dataloder = get_mnist_dataloaders(
64, mnist_train_dataset, mnist_test_dataset
)
Eu vou criar também uma função para nos permitir visualizar uma imagem desse conjunto de dados, utilizando para isso o matplotlib.
def plot_dataset_image(idx: int, dataset: Dataset):
image, label = dataset[idx]
image_reshaped = image.reshape(28, 28)
plt.imshow(image_reshaped, cmap="gray")
plt.title(label)
plt.show()
plot_dataset_image(4, mnist_train_dataset)

Quando retornamos a imgem direto do Dataset obtemos um tensor no formato:
- (C, W, H)
Porém, o matplotlib espera que se a imagem for colorida (RBG), ela tenha o seguinte formato:
- (W, H, C)
Então para facilitar, e como essas imagem já vem com apenas 1 channel, nós simplemente estamos considerando as dimensões W, H. Por isso você vai ver o método de reshape na função plot_dataset_image.
Transformações
Vamos vizualizar 4 transformações nos dados que podem ser feitas aplicando diretamente a operação de convolução:
- Desfoque gaussiano
- Detecção de contornos
- Detecção de linhas horizontais
- Detecção de linhas verticais
O ponto comum entre todas operações, é a necessidade de configuração de um kernel. Veja abaixo o kernel que gera um determinado resultado.



No Pytorch, uma forma de replicar essa operação é aplicando um método de operação convolucional:
def blurring_image(image: torch.Tensor, kernel_size: int = 3) -> torch.Tensor:
kernel = torch.ones(kernel_size, kernel_size) / kernel_size**2
return F.conv2d(image.unsqueeze(0), kernel.unsqueeze(0).unsqueeze(0))
# calling
image, _ = mnist_train_dataset[90]
new_image = blurring_image(image)
Você pode encontrar todas as outras operações nesse notebook. E abaixo temos o resultado das 4 transformações que foram citadas acima.

unsqueeze(0) nesses códigos de transformação das imagens. Isso é apenas para ajustar as dimensões durante as manipulações. Esse método basicamente cria uma nova dimensão mantendo o shape do formato inicial:Nossa primeira CNN 🔥 (sem pooling)
Bom, agora que nós temos os dados, vamo realizar o treinamento da nossa primeira CNN. Eu vou utilizar aqui três funções de ajuda do livro Inside Deep Learning, onde essas funções contêm alguns códigos que normalmente se repetem para todo tipo de treinamento de modelo de Deep Learning.
O que essas funções fazem?
- movem um objeto em python para o device correto
- loop de treino
- salvam alguns dados durante o treinamento: modelo, métricas de performance, etc.
movetorun_epochsimple_training_loop.
Agora, vamos criar o código do nosso modelo, passando também algumas constantes:
B = 32 # batch size
D = 28 * 28 # image dimensionality
C = 1 # number of channels
classes = 10
filters = 16
kernel_size = 3
fc_model = nn.Sequential(
nn.Flatten(), # (B, C, W, H) -> (B, C * W * H) = (B, D)
nn.Linear(D, 256),
nn.Tanh(),
nn.Linear(256, classes),
)
model_conv = nn.Sequential(
nn.Conv2d(C, filters, kernel_size, padding=kernel_size // 2),
nn.Tanh(),
nn.Flatten(),
nn.Linear(filters * D, classes),
)
Apenas a nível de comparação, vamos treinar os dois modelos (fully-connected e CNN):
loss_func = nn.CrossEntropyLoss()
cnn_results = train_simple_network(
model_conv,
loss_func,
mnist_train_dataloder,
mnist_test_dataloder,
score_funcs={"accuracy": accuracy_score},
device=device,
epochs=100,
checkpoint_file="./model/cnn_checkpoint.pth",
)
loss_func = nn.CrossEntropyLoss()
fc_results = train_simple_network(
fc_model,
loss_func,
mnist_train_dataloder,
mnist_test_dataloder,
score_funcs={"accuracy": accuracy_score},
device=device,
epochs=100,
checkpoint_file="./model/cnn_checkpoint.pth",
)
Caso esteja demorando muito o treinamento para 100 épocas, você pode diminuir o número de épocas. Mas, como resultado nós teremos algo semelhante ao do plot abaixo:
Apesar de ter obtido bons resultados, nosso modelo ainda é bem sensível há algumas mudanças no comportamento dos dados, como por exemplo, sensível a translação do objeto que estamos classificando (números).
Os números do dataset MNIST que estamos tentando prever estão todos centralizados, e com isso se algum número mudar de posição, provavelmente vai levar a uma variação na acurácia do modelo.
Verificando a movimentação do objeto
Vamos utilizar um método do numpy que faz essencialmente isso, o np.roll:
img_idx = 10
img, correct_class = mnist_train_dataset[img_idx]
img = img.reshape(28, 28)
img_lr = np.roll(np.roll(img, 4, axis=1), 1, axis=0)
img_ul = np.roll(np.roll(img, -4, axis=1), -1, axis=0)
Então, o que está acontecendo aqui é o descolando da imagem em uma duas direções distintas:
img_lr: lower rightimg_ul: upper left
Para ficar mais claro o que o np.roll faz, eu sempre gosto de rodar o método em um pedaço de código mais simples, nesse caso, em um array unidimensional, temos:
x = np.arange(10) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
np.roll(x, 2)
Agora, vamos ver então como ficaram todas as movimentações em comparação com a imagem original:
f, axarr = plt.subplots(1, 3)
axarr[0].imshow(img, cmap="gray")
axarr[1].imshow(img_lr, cmap="gray")
axarr[2].imshow(img_ul, cmap="gray")
plt.show()

Veja que nossa imagem já foi movimentada, vamos investigar a acurácia em cada uma das situações:
# creating a prediction function
model = model_conv.cpu().eval() # passing to cpu and eval mode to be simpler
def pred(model, img):
with torch.no_grad():
w, h = img.shape
if not isinstance(img, torch.Tensor):
img = torch.tensor(img)
# We need add some dimensions to the image so that it is in the correct shape
x = img.reshape(1, -1, w, h)
logits = model(x)
# We need to apply softmax to get the probabilities
y_hat = F.softmax(logits, dim=1)
return y_hat.numpy().flatten()
# calling
img_lr_pred = pred(model, img_lr)
img_pred = pred(model, img)
img_ul_pred = pred(model, img_ul)
print(
f"Predicted class for original image: {np.argmax(img_pred)} / Probability: {img_pred[np.argmax(img_pred)]}"
)
print(
f"Predicted class for left-right image: {np.argmax(img_lr_pred)} / Probability: {img_lr_pred[np.argmax(img_lr_pred)]}"
)
print(
f"Predicted class for up-left image: {np.argmax(img_ul_pred)} / Probability: {img_ul_pred[np.argmax(img_ul_pred)]}"
)
- imagem normal: 0.99
- lower right: 0.73
- upper left: 0.61
Para que nosso modelo possa ser mais robusto em relação a translação do objeto, vamos tentar aplicar um pooling na nossa arquitetura.
Nossa segunda CNN 🔥 (com pooling)
O pooling nada mais é que uma técnica que nos ajuda a ter uma propriedade chamada translation invariance, ou seja, o aprendizado do nosso modelo fica menos suscetível a movimentação do objeto de interesse.
De forma prática, aqui nós vamo estar utilizando o max pooling, onde é utilizado o valor máximo da matriz da imagem de input na camada de pooling. Pela imagem abaixo fica mais claro o que estou querendo dizer:

A partir do momento que aumentamos o K (input do método), acabamos tendo uma janela maior para retornar o valor máximo. Um ponto importante é que o pooling diminui o tamanho da imagem, então precisamos de cuidado pois ao final podemos machucar muito a representação do nosso problema, tendo uma perda muito grande de informação útil.
Nossa CNN com pooling e mais camadas, fica assim:
model_cnn_pool = nn.Sequential(
nn.Conv2d(C, filters, 3, padding=3 // 2),
nn.Tanh(),
nn.Conv2d(filters, filters, 3, padding=3 // 2),
nn.Tanh(),
nn.Conv2d(filters, filters, 3, padding=3 // 2),
nn.Tanh(),
nn.MaxPool2d(2),
nn.Conv2d(filters, 2 * filters, 3, padding=3 // 2),
nn.Tanh(),
nn.Conv2d(2 * filters, 2 * filters, 3, padding=3 // 2),
nn.Tanh(),
nn.Conv2d(2 * filters, 2 * filters, 3, padding=3 // 2),
nn.Tanh(),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(2 * filters * D // (4**2), classes),
)
# training
loss_func = nn.CrossEntropyLoss()
cnn_results_with_pool = train_simple_network(
model_cnn_pool,
loss_func,
mnist_train_dataloder,
mnist_test_dataloder,
score_funcs={"accuracy": accuracy_score},
device=device,
epochs=100,
checkpoint_file="./model/cnn_pooling_checkpoint.pth",
)
Nesse caso para a mesma imagem que foi transladada em diferentes posições, nós tivemos os seguintes scores:
- imagem normal: 0.99
- lower right: 0.94
- upper left: 0.73
Nossa terceira CNN 🔥 (com data augmentation)
Por fim, uma última estratégia que gostaria de trazer aqui é o Data Augmentation. E a ideia por de trás é basicamente a de expor o seu modelo ao maior número possível de varientes da imagem original, para que ele consigar ter um ótimo grau de generalização.
A sacada é que você não precisa necessariamente coletar novos dados, e sim manipular uma imagem para criar diferentes situações para ela:
- rotacionar
- ditorcer
- alterar brilho e contraste
- alterar cores do canal rgb
- aplicação de ruído
A lista é imensa e o torchvision tem um módulo que nos ajuda nisso, chamado transforms. Você também pode encontrar módulos de terceiros como o Albumentation, mas acho que independente da lib que você estiver utilizando, o importante mesmo vai ser escolher a transformação que faz sentido para o seu dado.
Digo isso por quê você pode aplicar uma transformação de brilho e contraste numa image, e o resultado ser uma imagem completamente ilegível, que dificilmente um humano vai conseguir distinguir o que é. Essas transformações precisam ser aplicadas considerando o “universo” de possibilidades de transformações que essas imagens podem sofrer.
Vamos visualizar como essas transformações se comportam no torchvision e em seguida vamos treinar nossa CNN, porém agora passando algumas transformações ao dado.
Transforms do torchvision
O código abaixo aplica algumas transformações ao nosso dataset:
sample_transforms = {
"Rotation": transforms.RandomAffine(degrees=45),
"Translation": transforms.RandomAffine(0, translate=(0.1, 0.1)),
"Shear": transforms.RandomAffine(0, shear=45),
"RandomCrop": transforms.RandomCrop((20, 20)),
"Horizontal Flip": transforms.RandomHorizontalFlip(p=1.0),
"Vertical Flip": transforms.RandomVerticalFlip(p=1.0),
"Color Jitter": transforms.ColorJitter(
brightness=0.5, contrast=0.5, saturation=0.5, hue=0.5
),
"Perspective": transforms.RandomPerspective(p=1.0),
}
pil_img = transforms.ToPILImage()(img)
f, axarr = plt.subplots(2, 4, figsize=(15, 10))
for i, (name, transform) in enumerate(sample_transforms.items()):
pil_img_transformed = transform(pil_img)
axarr[i // 4, i % 4].imshow(pil_img_transformed, cmap="gray")
axarr[i // 4, i % 4].set_title(name)
plt.show()

Treinando
Vamos ao que interessa! Como transforms, eu vou utilizar variação de rotação, translação e escala. Ao final disso, vamos converter a imagem para tensor.
train_transform = transforms.Compose(
[
transforms.RandomAffine(degrees=5, translate=(0.05, 0.05), scale=(0.95, 1.05)),
transforms.ToTensor(),
]
)
test_transform = transforms.ToTensor()
mnist_train_dataset_v2 = MNIST(
root="./data", train=True, download=True, transform=train_transform
)
mnist_test_dataset_v2 = MNIST(
root="./data", train=False, download=True, transform=test_transform
)
train_loader_v2 = torch.utils.data.DataLoader(
mnist_train_dataset_v2, batch_size=B, shuffle=True
)
test_loader_v2 = torch.utils.data.DataLoader(
mnist_test_dataset_v2, batch_size=B, shuffle=False
)
Como a arquitetura do modelo é a mesma, não vou repetir esse código aqui. Mas, ainda assim você precisa reeinstanciar o objeto, para que o Pytorch não utilize os pesos que já fora oriundos do treinamento passado.
A única diferença é que agora você precisa passar o train_loader_v2 e test_loader_v2 para a função train_simple_network.
Dito isso, nossos resultados foram:
- imagem normal: 0.99
- lower right: 0.99
- upper left: 0.53
Olha que interessante, nós conseguimos melhorar a acurácia para a previsão do lower right, porém, para o upper left acabamos piorando a situação. Isso pode ter acontecido por conta da transformação que foi aplicada na imagem durante o treinamento do modelo não refletir a situação da imagem que a gente gerou, manualmente, de translação.
Modelos pré-treinados
Espero que tenha consigo passar para você os principais conceitos relacionados as famosas CNNs e como codar o treinamento dessas arquiteturas. Apesar de conseguirmos ter resultados interessantes compondo o básico de uma arquitetura de CNN, esses resultados são ainda melhores quando utilizamos os modelos pré-treinados de CNNs mais complexas.
Não vamos entrar aqui no detalhe dessas arquiteturas mais robustas, mas vou deixar aqui um comando que você pode rodar para ter acesso há todos os modelo disponíveis no torchvision:
dir(models)
Isso vai te retornar uma lista imensa com todos os modelos geridos pelo hub do torchvision.
Por hoje foi isso, espero que tenha gostado, e no próximo artigo vamos falar sobre autoencoders!!